以前の投稿でKerasのインストール方法をまとめました
この記事ではkerasを使って簡単な学習プログラムを作り、グラフ表示やモデルの可視化方法についてまとめたものを記載します
実装したプログラムの概要
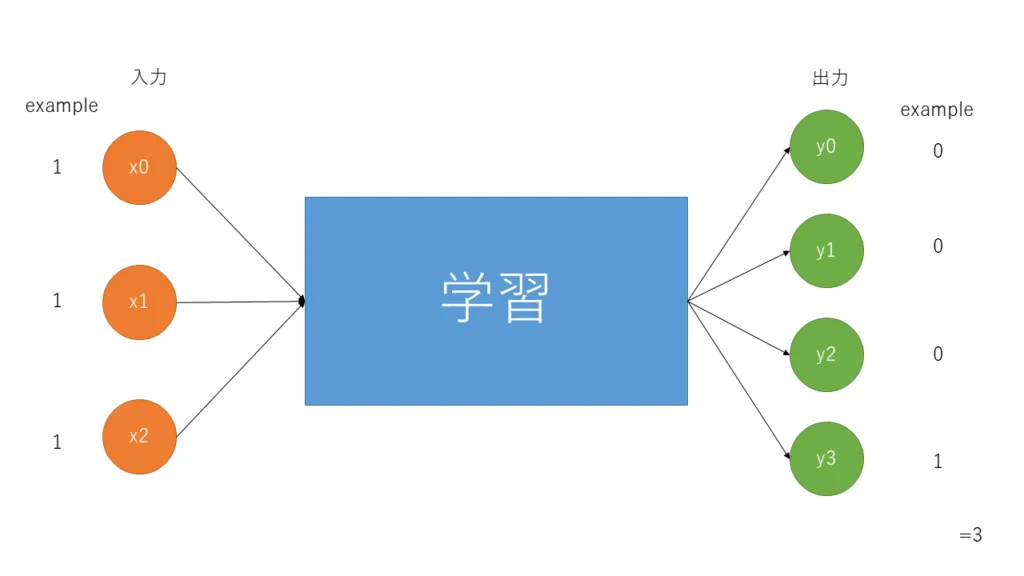
今回作成したプログラムは3個のデータを入力とし、学習を経て最後に4つ出力を行うプログラムです(合計値なら深層学習しなくても良いですが練習なので)
入力には、[0, 1, 0]や[1, 0 ,0]といったデータを入力としています
この3つを合計を出力としています(つまり3つの入力であるため、出力パターン(合計のパターン)は ‘0’ ‘1’ ‘2’ ‘3’となるため、出力を4パターンとしている)
出力について少し深掘りすると下記のように出力となります
0のとき : [1, 0, 0, 0]
1のとき : [0, 1, 0, 0]
2のとき : [0, 0, 1, 0]
3のとき : [0, 0, 0, 1]
上記のように値ごと区別(ラベル)されています
簡単なイメージ図は下記のような感じ
プログラム
前回の記事にてkerasを導入すればコピペで動くと思います
学習後は学習とテストデータに使用していない未知のプログラムを入れてどれくらいの認識力であるかを出力しています
プログラムの詳細
最初に学習用データを作成しています
今回は1000個のデータを作成し、ランダムで入力データを作っています
#乱数で0 1を出力しこれは配列化,このセットを1000コ生成
Data = np.random.randint(low=0, high=2, size=(DataNum, DataInput))学習用データを作成後、学習用データにラベルを作らなければならないためラベルを作ります
ランダムで作ったデータの合計値を計算し、np_utils.to_categoricalのでラベルにしています
EX:合計値が2の時は、[0, 0, 1, 0]と変換されます
#データラベルを作成
#kerasだとちょっと工夫が必要
#ラベル2であるとき -> [0. 0. 1. 0.] と変換
DataLabel = np.sum(Data, axis=1)
DataLabel = np_utils.to_categorical(DataLabel)学習用データを作成後、学習モデルを設計します
入力データが簡単なので隠れ層が一層の簡単な実装です
kerasはaddで層や活性化を記述することができるためとても簡単です
注意点として最初のaddのinput_dimは入力するデータと一致しなければなりません(当たり前だけど)
今回は入力データが3個なのでinput_dimには3が入っています
最後の最後の出力はラベルと同じ数です
#モデルの生成
model = Sequential() #初期化的
model.add(Dense(64, input_dim=DataInput)) #入力(input_dim)から隠れ層に何個渡すか DataInputに依存
#活性化
model.add(Activation('relu'))
#出力
model.add(Dense(DataOutput, activation='softmax'))
#コンパイル
model.compile('rmsprop', 'categorical_crossentropy', metrics=['accuracy'])
#学習
#Data:学習データ
#DataLabel:学習ラベル
#epochs:学習回数
#validation_split:バリデーションデータの割合
#shuffle:データのシャッフル
#batch_size:バッチ数
hist = model.fit(Data, DataLabel, epochs=3, validation_split=0.3, batch_size=1, shuffle=True)Activation(活性化関数)について触れると長くなるため、下記を参照すると良いです

model.compileとmodel.fit等の引数はコメントアウトでも説明していますが、公式をみると詳しく書いてあります
モデル作成後、テストデータを作成しどれくらいの認識力があるか評価します
はじめに学習に使っていない未知のデータとラベルをつくります
作り方は学習データと作り方は同じです
一応printにて作られたデータを表示しています
#未知のデータを生成
Test = Data = np.random.randint(low=0, high=2, size=(1, DataInput))
#未知ラベルの生成
TestLabel = np.zeros(DataOutput)
TestLabel[np.sum(Test, axis=1)] = 1
print("AnswerLabel:",TestLabel)
print("AnswerVal:", TestLabel.argmax())
print("----------------------")
モデルデータが未知のデータに対して認識しているか確認します
printにてscoreとscoreを元に合計値を出力(ScoreVal)しています
##推定
#テストデータ(Test)のみmodelにいれて結果を出力
#batch_size:バッチサイズ
#verbose:進行メッセージの表示 0=非表示, 1=表示
Result = model.predict(Test, batch_size=1, verbose=0)
print("Score:", Result)
print("ScoreVal:", Result.argmax() )
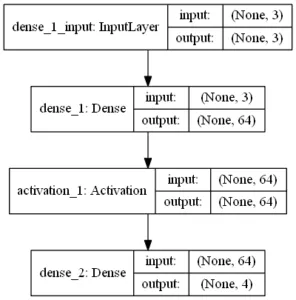
print("----------------------")最後に今回作ったモデルの図と学習済みのモデルの保存をしています
#モデルの図の生成
#show_shapes:データ数を表示させるか
plot_model(model, show_shapes=True, to_file='model.png')
#モデルの保存
#jsonとh5ファイルがでてくる
JsonString = model.to_json()
open("model_result_data.json", 'w').write(JsonString)
model.save_weights("model_result_data.h5")
print("Save Model..")コメントアウトしていますが、外すと精度と損失のグラフを表示します
#accとlossのグラフ生成
loss = hist.history['loss']
val_loss = hist.history['val_loss']
# lossのグラフ
plt.plot(loss, marker='.', label='loss')
plt.plot(val_loss, marker='.', label='val_loss')
plt.legend(loc='best', fontsize=10)
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
acc = hist.history['acc']
val_acc = hist.history['val_acc']
# accuracyのグラフ
plt.plot(acc, marker='.', label='acc')
plt.plot(val_acc, marker='.', label='val_acc')
plt.legend(loc='best', fontsize=10)
plt.grid()
plt.xlabel('epoch')
plt.ylabel('acc')
plt.show()出力
単純な学習なので簡単にlossや精度が良くなると思います
AnserVal(未知データの合計)とScoreVal(学習済みモデルから出力された値)が同一であることから認識はできているようです
> python .\SampleKera.py
C:\Users\******\AppData\Local\Programs\Python\Python36\lib\site-packages\h5py\__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.
from ._conv import register_converters as _register_converters
Using TensorFlow backend.
Train on 700 samples, validate on 300 samples
Epoch 1/3
2018-02-26 16:24:34.352121: I C:\tf_jenkins\workspace\rel-win\M\windows\PY\36\tensorflow\core\platform\cpu_feature_guard.cc:137] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX AVX2
700/700 [==============================] - 2s 3ms/step - loss: 0.9826 - acc: 0.6014 - val_loss: 0.7124 - val_acc: 0.9067
Epoch 2/3
700/700 [==============================] - 2s 2ms/step - loss: 0.5290 - acc: 0.9314 - val_loss: 0.3556 - val_acc: 1.0000
Epoch 3/3
700/700 [==============================] - 2s 2ms/step - loss: 0.2376 - acc: 0.9929 - val_loss: 0.1397 - val_acc: 1.0000
----------------------
AnswerLabel: [1. 0. 0. 0.]
AnswerVal: 0
----------------------
Score: [[0.945631 0.051894 0.00243 0.000045]]
ScoreVal: 0
----------------------
Save Model..作成したモデルは下記のようになります
学習済みモデルを他のプログラムで利用する
作成したプログラムは学習済みモデルを保存するプログラムも入れています
この保存したモデルを他のところで使いたいときは下記のようにします
from keras.models import model_from_json
#学習されたモデル
model_json = "model_result_data.json"
model_h5 = "model_result_data.h5"
#-----------------------------------------------
#学習済みモデルのロード
json_string = open(model_json).read()
model = model_from_json(json_string)
model.compile('rmsprop', 'categorical_crossentropy', metrics=['accuracy'])
model.load_weights(model_h5)
#--------------------------------------------学習済みモデルをロード後、認識テストするプログラムを下記にのせておきます
まとめ
ざっくりではありますが、kerasを利用した簡単なディープラーニングを記述しました
ディープラーニングで重要となる活性化やドロップアウト、については深く掘り下げていないため公式サイトや参考文献を参照してください
前回も紹介したとおりkerasはCNNとRNNもすることができるため、やってみてみてはいかがでしょうか
また、今回作ったプログラムはGitHubにのせているため参考にしてみてください

